POC des NetWorker-NMDA-OApp Moduls
Verfasst von Uwe W. Schäfer am 24. Mai 2022
Wie es der Zufall mal wieder so wollte, fragten in diesem Jahr zwei Kunden unabhängig voneinander, nach einem Prove Of Concept (POC) für den Einsatz des NMDA-OApp Moduls. In einem Fall für einen Einsatz mit PostgreSQL Datenbanken im zweiten Fall für MySQL Datenbanken.
Beide POCs konnten erfolgreich beendet werden, aber bevor wir uns mit den Details befassen ein paar kurze Infos zu dem NMDA-OApp Modul.
Mit der NetWorker Version 18.1 (2018) wurde in dem NetWorker „Modul for Database Applications (NMDA)“ die sogenannte OApp Erweiterung eingeführt. Diese ermöglicht es, mit Hilfe eines DataDomain Storage-Systems und dem zugehörigen BoostFS Modul, Datensicherungen und Wiederherstellungen der Datenbanken PostgreSQL, MySQL, MariaDB und MongoDB schnell, elegant und vor allem sicher auf ein externes Backup-Storage-System zu speichern.
Bei dieser für NetWorker neuen Art der Sicherung werden die vom Datenbankprodukt bekannten Sicherungs- und Wiederherstellungs-programme verwendet, aber die Daten sind nach der Sicherung nicht mehr auf der lokalen Platte des Datenbank-Systems sondern auf der DataDomain und auf einem NetWorker-Medium.
Vorteile:
- Alle Sicherungen (Voll und Log-Sicherungen) werden mit den bekannten NetWorker-Eigenschaften verknüpft. Im einzelnen sind das:
- Retention Zeiten
- Cloning auf eine 2‘te Data-Domain
- Integration der Sicherung in die Medien-Datenbank und damit Such-Möglichkeiten über die Sicherungsattribute
- Auch eine Wiederherstellung auf einen definierten Zeitpunkt (Recover-Until-Time) werden durch die OApp Erweiterung ermöglicht.
Nachteile:
- Die Installation und Konfiguration des benötigten BoostFS Moduls und der benötigten Skripte ist ein wenig knifflig.
- Für eine Wiederherstellung müssen Anpassungen in Wiederherstellungs-Skripten vorgenommen werden.
Hier ein kurzer Abriss der benötigten Installations- und Konfigurations-Schritte beim Einsatz des Moduls mit PostgreSQL Datenbanken:
- Installation der benötigten NetWorker und DataDomain Pakete
- BoostFS Konfiguration
- Lockbox konfigurieren
- BoostFS für PostgreSQL konfigurieren
- NetWorker NMDA Config Files anlegen
- NetWorker Ressourcen anlegen
- Postgres Config File anpassen
Die SaveSets einer erfolgreichen PostgreSQL „full“ und Log-Sicherungen in der NetWorker Medien-DB:
> mminfo -ot -v -c sles12sp5-1
pgres.005 sles12sp5 02/17/22 55 MB cr full PostgreSQL_nsr_full
pglog.005 sles12sp5 02/17/22 16 MB cr txnlog PostgreSQL_nsr_txnlog_1040
pglog.005 sles12sp5 02/17/22 16 MB cr txnlog PostgreSQL_nsr_txnlog_1041
pglog.005 sles12sp5 02/17/22 2 KB cr txnlog PostgreSQL_nsr_txnlog_1041.0028.backup
Nötige Schritte für einen Point in Time Recover:
- Sicherungszeit (savetime) und SaveSet-Name des gewünschten Backup in der Config-Datei eintragen
- Relocation-Destination vorbereiten
- DB-Stoppen
- PostgreSQL Data Verzeichnis entfernen
- NetWorker NMDA Recover Kommando starten
- Wiederhergestellte Daten in das PostgreSQL-Data Verzeichnis umziehen
- Definitionsparameter in der postgresql.conf editieren
- restore_command
- recovery_target_time
- Postgres Signal Datei anlegen
- DB Starten
- Postgres Log File kontrollieren
- Postgres Signal Datei entfernen
- PostgreSQL Config File editieren
- PosgreSQL Dienst neu starten
Log-Ausgabe eines erfolgreichen Point in Time Recovers
> less data/log/postgresql-2022-02-17_104617.log
starting point-in-time recovery to 2022-02-17 10:30:00+01
The recovery completed successfully.
restored log file "1046" from archive
redo starts at 0/46000028
consistent recovery state reached at 0/46000138
database system is ready to accept read only connections
The recovery completed successfully.
restored log file "1047" from archive time 2022-02-17 10:30:24.525416+01
recovery stopping before commit of transaction 13283,
pausing at the end of recovery
HINT: Execute pg_wal_replay_resume() to promote.
FAZIT:
Die oben gezeigten Konfigurations-Schritte haben nicht den Anspruch vollständig und ausreichend zu sein, sie sollen Ihnen nur die Komplexität des Themas vermitteln, ihnen aber auch zeigen, dass das Ergebnis den Aufwand lohnt.
Sollten Sie weitergehende Fragen zu dem Einsatz des NMDA-OApp Moduls haben oder selbst einen POC in Ihrem Hause wünschen, so scheuen Sie sich nicht, den Autor zu kontaktieren.
Visualisierung von NetWorker-Logs und System-Stati
Verfasst von Uwe W. Schäfer am 21. Dezember 2020
Visualisierung und Management von NetWorker Log- und Raw-Dateien sowie Systemparametern
-
Einleitung
-
Das Ergebnis
Eine WWW-Oberfläche in der:
- alle wichtigen NetWorker Umgebungsparameter auf einen Blick ersichtlich sind.
- es möglich ist die daemon.raw Meldungen zu filtern, zu bearbeiten und bei definierten Meldungen
automatische Aktionen einzuleiten. - es möglich ist, Meldungen nach dem Status (NEW, ACCEPTED, ...), dem Verursacher (nsrexecd,
nsrd, ...), nach Meldungs-Texten und ausgewählten Zeiträumen, zu filten und nach allen gezeigten
Spalten, zu sortieren. - es möglich ist den zeitlichen Verlauf von System-Ressourcen der NetWorker-Server Maschine graphisch zu betrachten

- es möglich ist Datensicherungslangläufer (Long Running Jobs anzeigen zu lassen.

- es möglich ist den Speicher- und Swap-Verbrauch der NetWorker-Server Maschine des letzten Monats visualisiert zu betrachten




-
Weitere Module
- Überwachung der RetentionLock Definitionen in den NetWorker Workflow-Actions
- Visualisierung der NetWorker Rap.log Datei
- Kontrolle der installierten NetWorker Client- und Modul-Versionen
- Berechnung der DataDomain DeDup-Werte pro Client und SaveSet. Gruppierung der Clients zu Abrechnungzwecken.
-
Die Zukunft
Weitere Überwachungsparameter sind in Planung oder bereits in Arbeit.
zum Beispiel:
- Erkennen von Backup Anomalien
- Überwachung der Bootstrap Sicherungen
- Kontrolle der RetentionLock Funktionalität bei Datenbank Sicherungen
- Visualisierung der NetWorker Client- und Modul-Logdateien
- ...
Wer für die Sicherung einer größeren Firma verantwortlich ist, möchte frühzeitig mitbekommen, wenn
das Backup-System in eine Schieflage gerät. Um das zu erreichen, reicht es nicht, nur die Meldun-
gen der Sicherungen zu kontrollieren, sondern der Administrator sollte auch die Protokolle der Back-
up-Software und des Betriebssystems betrachten. Zusätzlich sollten die Betriebssystem-Parameter,
wie Hauptspeicherverbrauch, Netzwerkauslastung und Ähnliches im Auge behalten werden.
Ein NetWorker Administrator ist heutzutage aber schon rein zeitlich nicht in der Lage, alle System-
protokolle und die NetWorker-Protokolle täglich durchzuarbeiten. Die Überwachung läuft folglich
auf eine Symptom-Bekämpfung hinaus. Wenn ein akutes Problem auftaucht, z.B. eine Sicherung wird
wiederhollt abgebrochen, dann wird eine Analyse gestartet. Oft wäre das Problem aber bereits im
Vorfeld zu erkennen gewesen. Man hätte die Backup Probleme vermeiden können, wenn die betref-
fenden Meldungen früh genug erkannt worden wären.
Ein Beispiel:
Ein Kunde berichtete mir in einer meiner Workshops, dass die NDMP Sicherungen in seiner Firma seit
längerem ein Zeitfenster-Problem haben. Früher wäre alles ohne Probleme gelaufen, aber seit einiger
Zeit würden die NDMP Sicherungen zu lange brauchen.
An diesem Problem wurde schon seit Wochen herumgedoktert, auch mit externen Support. Aber leider
hatten alle Beteiligten immer nur im Umfeld des Storage-Systems und des NDMP-Workflows nach
Fehlern gesucht. Das eigentliche Problem wurde aber nicht entdeckt. Dabei war das Problem in der
NetWorker Protokoll-Datei (daemon.raw) durchaus ersichtlich, wenn man danach gesucht hätte. Die
Ursache des beschriebenen Problems in diesem Beispiel war nicht der NetWorker-Server oder eine
Konfiguration im NetWorker. Die Ursache des Problems war dem Austausch von Netzwerk-Kompo-
nenten und damit veränderten Netzwerk-Routen geschuldet. Durch diese Änderung in der Peripherie
konnten einige NetWorker-Client Maschinen die DataDomain Systeme nicht mehr direkt erreichen.
Es fand folglich kein Client-Direct-Backup mehr statt, sondern die Maschinen sendeten ihre Daten
zum NetWorker-Server und dieser übergab die Daten dann an die DataDomain. Durch dieses, um
mindestens 90% höhere Datenaufkommen, waren die Netzwerk- und System-Komponenten am Net-
Worker-Server so stark belastet, dass beim Start der NDMP Sicherungen keine Kapazitäten mehr frei
waren. Wie gesagt, die Meldungen, dass die Client-Sicherungen keinen direkten Weg mehr für ihr
Backup hatten, waren in den Logs ersichtlich. Es hat nur keiner bemerkt.
Das Auffinden entprechender Meldungen in der NetWorker daemon.raw wird dadurch erschwert,
dass alle NetWorker Daemonen ihre Standard-Error-Ausgabe in diese Datei schreiben. Wenn es dann
noch ein paar Maschinen gibt deren Client-Zertifikat fehlerhaft im NetWorker eingetragen ist, sieht
man schnell den Wald vor lauter Bäumen nicht mehr. Einige Tausend Meldungen pro Tag sind keine
Seltenheit. Hier die Spreu vom Weizen zu trennen war folglich das Ziel des vorliegenden Tools.
Sollten sie weitere Fragen oder Interesse an einer Live-Demo des Tools haben so wenden Sie sich am besten per Mail an den Autor.
NetWorker Health-Check
Verfasst von Uwe W. Schäfer am 15. Dezember 2020
In diesem von Corona bestimmten Jahr, fanden leider kaum NetWorker-Workshops statt. Doch hierdurch ergab sich auch die Zeit und die Möglichkeit, sich mit anderen Themen rund um die Datensicherung mit NetWorker zu beschäftigen.
Im August und November diesen Jahres, durfte ich bei zwei großen NetWorker-Kunden (mit jeweils mehr als 10 NetWorker-Servern) einen NetWorker Health-Check durchführen. Beide Firmen waren der Meinung, an sich läuft ihre Datensicherung weitestgehend fehlerfrei und problemlos. Meine jeweils viertägige Analyse an ausgewählten NetWorker-Servern ergab jedoch in beiden Fällen eine längere Liste an erkannten Problemen und Verbesserungsmöglichkeiten.
Der Schlüssel zu diesen Erkenntnissen waren
-
eine Analyse der NetWorker Ressourcen
-
eine konsequente Filterung der NetWorker Daemon.raw Dateien
-
eine Analyse der Sicherungszeiten (Sicherungsdauer einzelner SaveSets)
Die Daemon.raw Datei
Diese von allen NetWorker Dämonen beschriebene Datei wird meist viel zu selten oder auch gar nicht für tägliche Analysen herangezogen. Bei akuten Fehlern schaut der Administrator zwar zwangsweise in sie hinein, aber einfach mal so?
Dabei sind hier durchaus interessante und auch wichtige Meldungen enthalten, die auf nicht erkannte Probleme hin deuten oder aufzeigen können, wo noch Konfigurations-Verbesserungen möglich und nötig sind.
Die Probleme bei der Analyse dieser Log-Datei sind:
-
ihre schiere Größe (wie gesagt alle NetWorker Dämonen schrieben hier gleichzeitig hinein)
-
das Verhältnis zwischen unwichtigen Meldungen und relevanten Meldungen
-
das Format
Die Kunst beim Auswerten der Datei bestand folglich darin, die Spreu vom Weizen zu trennen. Soll heißen, die unwichtigen oder bereits bearbeiteten Meldungen aus der zu untersuchenden Datei heraus zu filtern, um im Anschluss die übrigen Meldungen zu sichten und zu bewerten.
Die Sicherungszeiten
Wenn eine Sicherung länger als das eingestellte Workflow-Intervall dauert, bekommt das der Backup-Administrator in den meisten Fällen gar nicht mit. Dies liegt darin begründet, dass NetWorker seit der NetWorker Version 9, in diesen Fällen keine Benachrichtigung (Notification) mehr versendet. Um diese Probleme folglich zu ermitteln, muss man die NetWorker-Medien-DB befragen. Mit einem entsprechendes Skript kann man dann die Intervall-Zeiten des jeweiligen Workflows mit den tatsächlichen Sicherungszeiten der zugehörigen Sicherungen vergleichen. Aber auch eine Sicherung die zwar im Intervall fertig wird, aber mehr als z.B. 16 Stunden dauert, kann für eventuelle Wiederherstellungen zum Problem führen! Für diese erkannten Sicherungsprobleme galt es im Anschluss die jeweilige Ursache und eine mögliche Lösung zu finden.
Die Lösungen konten hierbei leider aus keinem Kochrezept entnommen werden, sondern sie bedurften teils längeren Analysen und Tests. Vor allem, weil es einmal um Filesystem- dann um Datenbank- aber auch um NDMP Sicherungen ging.
Die Methoden und Erkenntnisse dieser beiden Health-Checks sind unter anderem in unser neues NetWorker Log-Analyse und Monitoring Tool eingeflossen. Dieses aus einem WWW-Server und einer Datenbank, sowie 3 Analyse-Daemonen bestehenden Produkt, filtert nicht nur die Meldungen der jeweiligen Daemon.raw Datei vor, sondern es bietet interaktiv die Möglichkeit diese Filter selbst zu erweitern. Zusätzlich werden Sicherungslangläufer und weitere Probleme der NetWorker-Maschine analysiert und dargestellt. Mehr zu diesem Tool erfahren sie hier in Kürze.
Sollten auch Sie einen NetWorker Health-Check wünschen, so wenden Sie sich einfach per E-Mail an den Autor.
NetWorker Capacity Monitoring
Verfasst von Uwe W. Schäfer am 13. November 2019
Wie im letzten Blog (NetWorker Session Monitoring) bereits erwähnt, haben wir unsere Backup-Monitoring Landschaft um eine dritte Komponente erweitert. Zusätzlich zum Monitoring der DataDomain-Streams und den NetWorker Sessions, gibt es jetzt auch die Möglichkeit, den Verlauf der NetWorker „Used Capacity“ für den kompletten NetWorker Server, aber auch für jeden einzelnen Client graphisch zu betrachten.
Sollten Sie ihre NetWorker -Lizenzen auf Basis einer Kapazitäts-Lizenz bezahlen müssen, so ist es auch für sie interessant zu wissen, wie sich die Kapazität der einzelnen zu sichernden Maschinen im Lauf der Zeit verändert. Die NetWorker Reporting Mechanismen sind hierbei leider keine große Hilfe. Diese sind ja noch nicht einmal in der Lage, die aktuell korrekte Kapazitäts-Lizenz-Größe für einen NetWorker-Server zu berechnen (siehe hierzu unseren Blog „NetWorker Volumen Lizenz“ Berechnung).
Hier ein Beispiel-Bild der Lizenz relevanten Sicherungsgrößen („Used Capacity“) für einen SAP-Client und einen MS-SQL-Client.
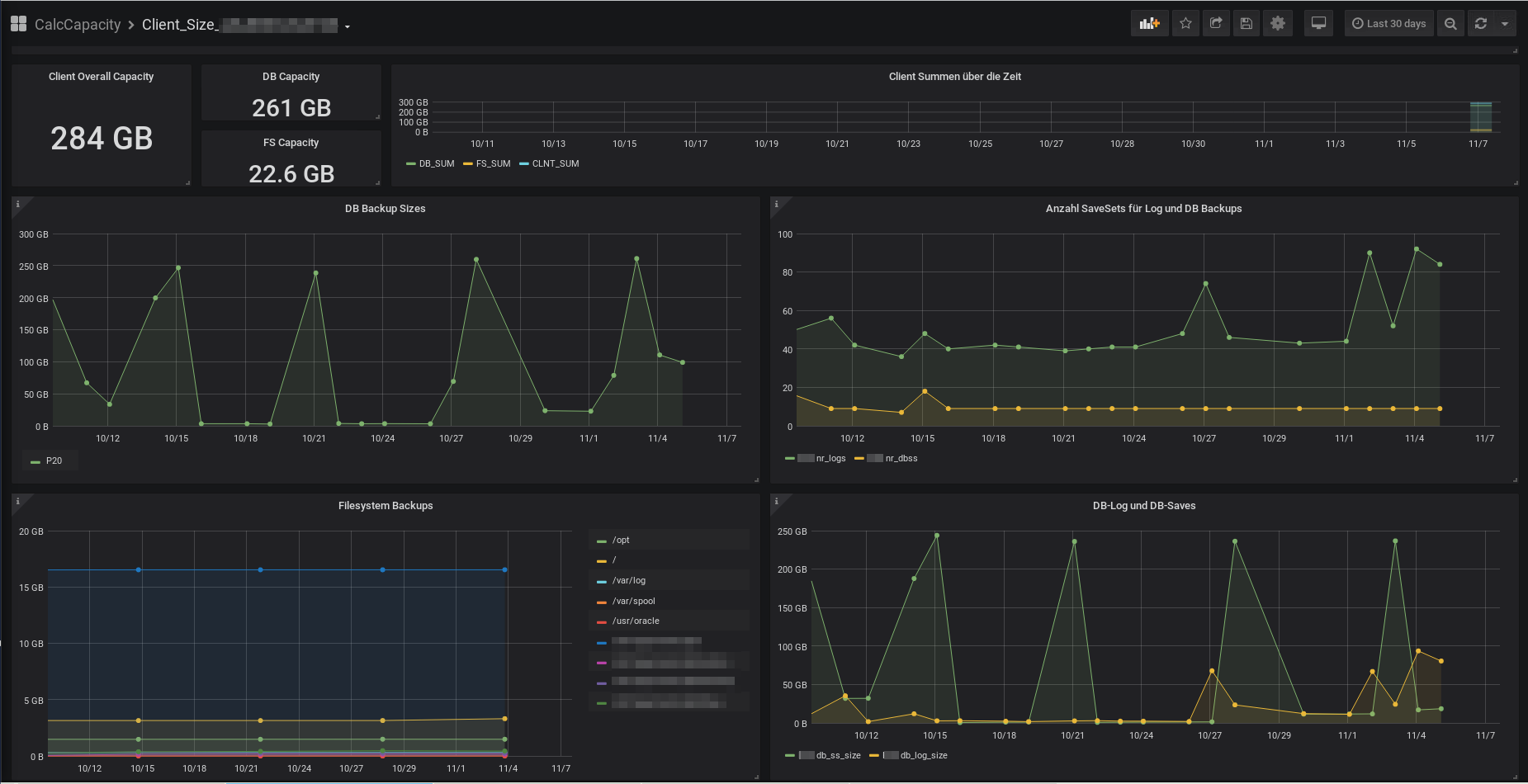
SAP Client
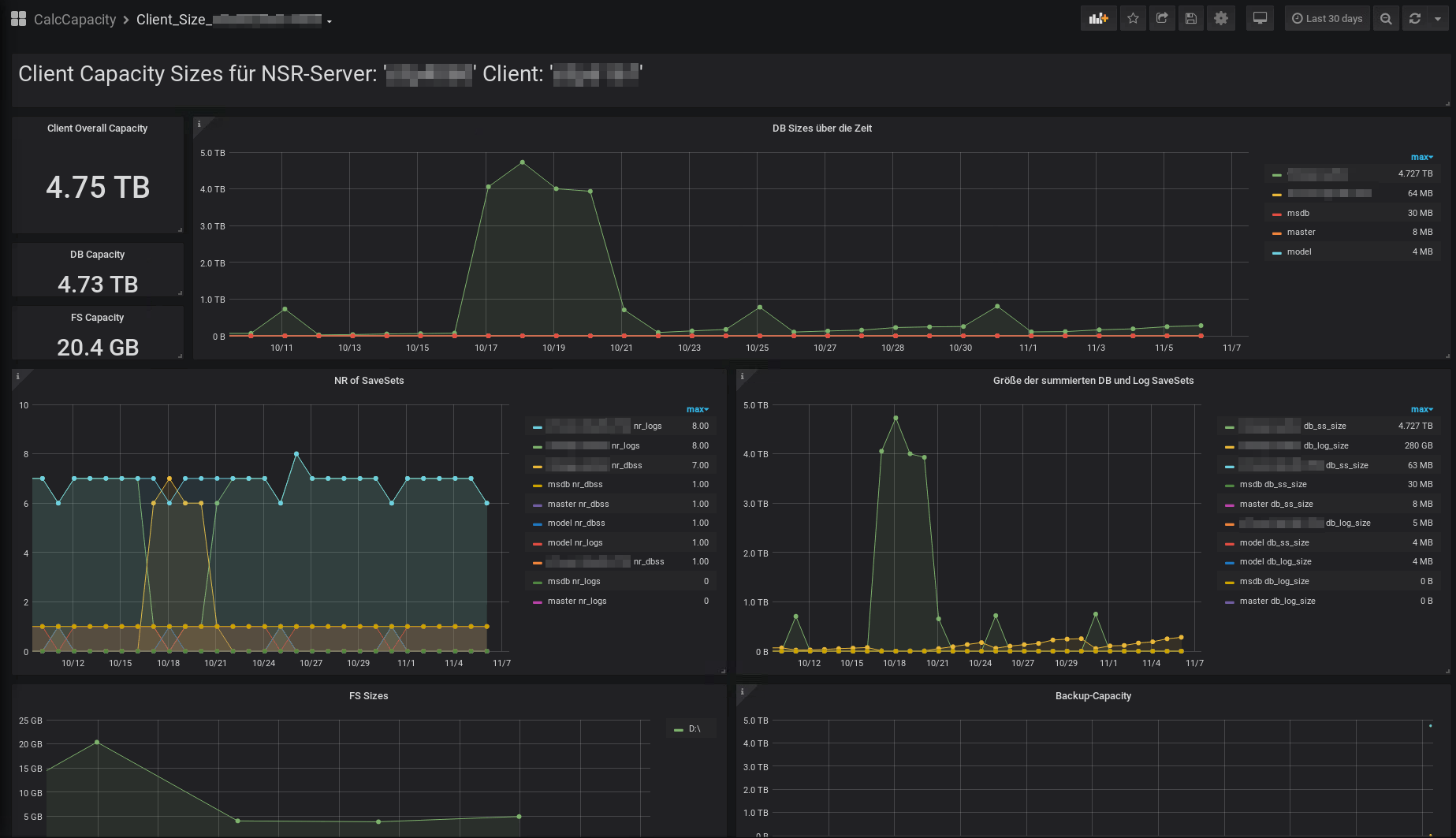
MS-SQL Client Capacity
Aus den obigen Graphiken können zum einen der aktuell für die Berechnung der Volumen-Lizenz relevante Wert, zum anderen die tagesaktuellen Größen der Sicherungsmengen für die Filesystem-Sicherungen, aber vor allem auch für die Datenbank-Sicherungen entnommen werden. Für die Datenbank-Sicherungen erhalten sie nicht nur die zugehörigen Sicherungsgrößen, sondern auch die Anzahl der Sicherungs-SaveSets für die DB und Log-Sicherungen. Hierdurch sollte sich nicht nur das Wachstum der Datensicherungsmenge über die Zeit ermitteln lassen, sondern es sollte auch möglich werden, azyklische Sicherungsmengen, die durch Datenbank-Aktivitäten, wie das neu Befüllen einer Datenbank mit aktiver Log-Sicherung zu erkennen.
Die Grafiken werden anhand von Daten einer PostgresDB und dem Darstellungs-Tool Grafana erzeugt. Die Datenbank wird mit einer Erweiterung des Schäfer & Tobies eigenen Capacity Berechnungstools gefüllt und in einem auf DOCKER basierendem Datenbank-Image eingetragen.
Die oben gezeigten Dashboards können dabei für jeden Client mit Hilfe eines Python-Skriptes voll automatisiert aufgebaut werden. Die Ermittlung der Client-Capacity kann zum Beispiel einmal pro Woche oder einmal pro Monat erfolgen. Die Erzeugung der Daten kann dabei auf jeder beliebigen Linux NetWorker-Client-Maschine durchgeführt werden.
Sollten Sie Fragen zu der hier dargestellten Analyse-Software haben, so senden sie uns bitte unverbindlich eine E-Mail. Wir werden uns mit Ihnen in Verbindung setzen und wenn gewünscht, auch gerne eine Demo der Möglichkeiten mit Hilfe einer Telefon-Konferenz durchführen.
Weitere Informationen zu unseren Monitoring-Tools erhalten sie auch im BLOG „DataDomain Stream Monitoring“ und im Blog „NetWorker Session Monitoring“.
