NetWorker Windows TO Linux Migration
Verfasst von Uwe W. Schäfer am 3. Juli 2023
Erste erfolgreiche Migration eines Windows basierten NetWorker-Servers auf ein Linux System mit Hilfe der in NetWorker V19.9 neu eingeführten Migrations-Kommandos.
Durch das verstärkte Auftreten von Male-Ware Angriffen wird der Wunsch und auch der Druck immer größer, bestehende Windows-NetWorker-Server auf ein Linux-System zu migrieren.
Wer schon einmal einen verschlüsselten NetWorker-Server wieder ans rennen bringen musste (so wie ich für einen unserer Kunden ;-/) weiß, es ist keine gute Idee ein Backup System auf dem OS laufen zu haben, das am allermeisten unter den Verschlüsselungs-Angriffen zu leiden hat. Wenn man dann noch berücksichtigt, dass die Datensicherung eines der ersten Angriffsziele der Erpresser ist, (wenn der angegriffene seine Daten nicht wiederherstellen kann, ist er natürlich eher bereit das Erpressergeld zu zahlen), sollte jedem klar sein, dass auch die Plattform der Backup-Software so sicher wie möglich sein muss. Und da ist man mit einem Linux-System wesentlich sicherer unterwegs! Mir ist zumindest bisher kein durch einen Verschlüsselungstrojaner verschlüsseltes Linux-System bekannt geworden!
Bis zur NetWorker-Version 19.9 war die Migration von Windows zu Linux für einen NetWorker-Server ein Albtraum. Aber mit den neu eingeführten Kommandos nsrimportmmdb und nsrimportclient, sowie einer DataDomain als Backup-Storage lässt sich eine NetWorker-Server Migration ohne Einschränkungen durchführen. Klar, es sind einige Vor- und Nach-bereitungen nötig, aber mit einer guten Planung kann die Downtime des NetWorker-Servers während der eigentlichen Migration auf wenige Stunden begrenzt werden.
Die Vorbereitungen umfassen hierbei folgende Arbeiten:
- die Anpassung der Client „servers“ Dateien
- den Aufbau des neuen Linux-NetWorker-Servers
- die Übernahme der benötigten NetWorker-Ressourcen (natürlich Script gesteuert)
- das Erstellen einer schreibbaren Kopie des Sicherungs-Mtrees auf der DataDomain (hierfür wird kein zusätzlicher Platz auf dem Storage-System benötigt!)
- eine erfolgreiche Test-Migration (inclusive Test-Wiederherstellungen am neuen Server)
- Migration der NetWorker Lizenz auf das neue System
Die eigentliche Übernahme besteht dann nur noch aus:
- dem still legen des Windows-NetWorker-Servers
- der erneuten Kopie des DataDomain Mtrees
- der Migration existierender vProxy Systeme
- der Migration evtl. vorhandener StorageNodes und deren Laufwerke
- Aktivieren des neuen Servers
Die Nachbearbeitungen sind:
- Übernahme der letzten Indices
- Anpassung der Notifications
- Löschen des „alten“ Windows Mtrees auf der DataDomain
- ...
Wichtig zu erwähnen ist, dass die Migration immer auf einem doppeltem Boden aufgesetzt ist. Zu jeder Zeit kann diese unterbrochen werden, wenn eine bisher ungeahnte Problematik auftritt oder zum Beispiel ein Passwort für die Wiederherstellung der Lockbox nicht zu bekommen ist. Wichtig ist daher genügend Zeit für Recover und evtl. auch Backup-Tests vor der eigentlichen Migration einzuplanen.
Sollten auch Sie Ihren NetWorker-Server noch auf einem Windows-System betreiben und möchten diesen auf ein Linux-System migrieren lassen, dann melden Sie sich doch unverbindlich beim Autor dieses Blogs.
Migration von DataDomain Systemen mittels Collection-Replication
Verfasst von Uwe W. Schäfer am 8. Oktober 2020
Die Corona Zeit hat uns weiterhin alle im Griff, so gab es für mich seit März keine Workshops im Hause qSkills (lediglich 3 virtuelle NetWorker Workshops fanden statt) und auch die vor Ort Einsätze bei Kunden beschränkten sich auf genau 2 HealthChecks.
Aber einige Dinge lassen sich auch in diesen Zeiten nicht bremsen, so zum Beispiel das Datenwachstum in den Unternehmen. Daher stand bei einem unserer Kunden ein Austausch der beiden DataDomain Systeme gegen neuere, größere Modelle an. Um genau zu sein, sollten zwei DD6400-er Modelle mit 4-TB Platten-Shelfs gegen zwei DD9800-er Modelle mit 8 TB Platten ersetzt werden.
Im Normalfall kann man bei einem Upgrade der DataDomain-Systeme einfach einen Head-Swap (Austausch der Betriebssystem-Einheit) durchführen, wodurch keine Datenmigration nötig wird und alle angeschlossenen Backup Systeme nach dem Tausch der Einheit weiter arbeiten können wie zuvor. In dem hier beschriebenen Fall, konnte dieses Verfahren aber leider nicht durchgeführt werden, weil die „alten“ Platten-Shelfs nicht an den neuen Kopf angeschlossen werden konnten. Wären auf den DataDomain-Systemen ausschließlich NetWorker Server im Einsatz gewesen, so hätte eine Lösung in einer schleichenden Übernahme der Daten mittels Cloned-Control-Replication (CCR) und einer NetWorker basierten Migration der Langzeitsicherungen bestehen können. Aber der Kunde ist Dienstleister und hat außer 3 NetWorker Servern, 3 weitere Backup-Applikationen (VEEAM, DD-Boost for EAPP und VRanger) auf Basis von DD-Boost mit Mtree-Replikationen im Einsatz. Zudem gibt es auch noch reine CIFS-Shares mit Mtree-Replikationen. Ziel des Systemaustausches war es aber dennoch: Alle Backup-Systeme sollten nach der Migration ohne Datenverlust und OHNE Konfigurationsänderungen wieder an den Start gehen können.
Es war folglich eine Migration der Daten mit einer Übernahme der Konfigurationen von den Alt-Systemen zu den Neu-Systemen nötig. Die Herausforderung bestand folglich darin:
-
alle auf den beiden „alten“ DataDomain befindlichen Daten auf die beiden „neuen“ Systeme zu kopieren
-
die Namen der „Alt-Systeme“ auf die „Neu-Systeme“ zu übernehmen
-
die bestehenden Replikations-Beziehungen zwischen den DataDomain Systemen zu erhalten und auf die neuen Systeme zu übernehmen
-
die Migration so zu gestalten, dass nach der erfolgreichen Migration alle Backup-Applikationen nahtlos mit den neuen Systemen weiter arbeiten können.
Wie geht man in einem solchen Falle vor?
Das DataDomain-Betriebssystem kennt neben den oben bereits erwähnten Replikationsarten, Mtree-Replikation und CCR die „altertümliche“ Art der Collection-Replikation. Diese Replikationsart kopiert auf Block-Ebene alle Daten einer DataDomain auf eine zweite DataDomain. Hierbei werden alle Mtrees, deren Snapshots und auch die lokalen Benutzer und sonstigen Konfigurationen mit kopiert. Auf den neuen Systemen sollten folglich nach der erfolgreichen Kopieraktion alle Daten und Konfigurationen der „alten“ Systeme zur Verfügung stehen. Der einzige größere Punkt wäre demnach die Übernahme der Netzwerk-Konfiguration und die Umbenennung der Systeme. So weit die graue Theorie, doch wie so oft liegt die Tücke im Detail. Doch dazu später mehr!
Meine erste Idee für eine erfolgreiche Umsetzung der obigen Aufgabe war natürlich ein Test der Migration mit virtuellen DataDomain-Systemen. ABER nachdem ich eine passende Test-Umgebung aufgebaut hatte, gab mir das virtuelle DataDomain-Betriebssystem zu verstehen, dass eine Collection-Replikation mit virtuellen Systemen nicht unterstützt wird.
Also war mal wieder eine Operation am offenen Herzen nötig. Frei nach dem Motto „No Risk No Fun“, setzte ich folglich die Collection-Replikation zwischen den Source-DataDomain- und den Destination-DataDomain-Systemen auf. Hierfür ist zwar eine DownTime aller beteiligten Backup-Systeme von Nöten (das Filesystem der DataDomain muss vor dem Aufsetzen der Collection-Replikation disabled werden), aber diese hält sich zeitlich in Grenzen und war auch nur ein kleines organisatorisches Problem.
Nach dem Aufsetzen der Replikation bestand die Aufgabe zunächst nur darin, zu beobachten, mit welcher Geschwindigkeit die Daten kopiert werden und ob evtl. die Datenrate eingeschränkt werden sollte, um die Netzwerke nicht zu überfordern. Doch dank 10-GB Ethernet gab es keine Last-Probleme und die 4 Systeme waren nach einigen Tagen synchron.
Der Tag des CutOver (Übernahme der kompletten Funktionalität auf das jeweils neue System) war schließlich da. Die Downtime für alle Backup-Syteme war vorsichtshalber für einen ganzen Arbeitstag eingeplant. Jetzt wurde es spannend. Wichtig für eine erfolgreiche Übernahme der Mtree-Replikationen ist es, vor der Unterbrechung der Collection-Replikation auf allen Mtrees einen Snapshot zu generieren. Auf diesem Snapshot kann die jeweilige Mtree-Replikation nach dem CutOver wieder aufgesetzt werden. Eine Beschreibung zu diesem Verfahren findet man hier (Data Domain: MTREE resync after Collection replication cutover). Folglich legten wir für jeden Mtree (16 an der Zahl) ein Snapshot an und kontrollierten das diese auch auf den Ziel-Systemen vorhanden waren. Nach der erfolgreichen Kontrolle wurde der BREAK der Collection-Replikation durchgeführt. Auch hierfür muss zunächst das Filesystem disabled werden. Nachdem die Filesysteme auf den neuen DataDomain-Systemen wieder aktiviert (enabled) wurden, hat man auf diesen Systemen ein voll funktionsfähiges Filesystem mit allen Mtrees und Benutzern der Alt-Systeme.
Also ran an die Umbenennung der Alt-Systeme in vorher vorbereitete Backup-Namen und Adressen. Anschließend konnten die Neu-Systeme die Namen und Adressen der altem Systeme bekommen. Diese Arbeiten müssen natürlich über die Management-Interfaces der DataDomain Systeme durchgeführt werden, da man sich ja sonst den Boden unter den Füßen wegzieht. Der erste Schreck war jedoch, dass man nach dem Umbenennen der Neu-Systeme diese nicht erreichen konnte. Eine kurzes Innehalten und reflektieren des Themas ergab dann schnell, das dieses Problem im ARP-Cache der Ethernet-Switches zu finden war. Diese Komponenten hatten natürlich noch die alten MAC-Adressen zu den alten IP-Adressen gespeichert und ließen die Kommunikation erst mal nicht zu. Nachdem dieses Thema erledigt war, konnte man sich an die Wiederherstellung der Replikationen begeben.
Wenn das oben erwähnte Dokument dieses Vorgehen auch etwas kurz ab handelt, war dieser Punkt eher eine Fleiß-Aufgabe. Auf den neuen Systemen ist nämlich zunächst nichts von den ‚alten‘ Mtree-Replikationsbeziehungen zu sehen. Diese müssen folglich zunächst auf beiden Systemen bekannt gemacht werden. Hiernach kann man durch die bestehenden Snapshots und die Funktion Resync die vorherige Beziehung wieder aktivieren.
Diese Schritte mussten für jede Mtree-Replikationsbeziehung separat durchgeführt werden. Wie gesagt, Fleißarbeit und volle Konzentration waren hier gefragt.
Aber dann der Schock, wo waren die für die DD-Boost Kommunikation benötigten Storage-Units?
Die Mtrees auf denen die StorageUnits zum Beispiel für den NetWorker-Backups basieren, waren da, aber die logische DD-Boost-Einheit „StorageUnit“ war von der Collection-Replikation nicht übertragen worden. Zumindest war von diesen nichts zu sehen! Ein Anlegen dieser StorageUnits auf den bereits bestehenden Mtrees verweigert das DataDomain-OS sowohl aus dem GUI als auch auf der CLI Ebene. Eine Recherche auf den Dell/EMC Support-Seiten konnte leider auch nicht weiter helfen. Ein Hilferuf in die EMC-Community ergab zunächst die Idee, den bestehenden Mtree mittels Fastcopy in eine neue StorageUnit zu kopieren, hierbei könnte man die alte zunächst umbenennen und die Kopie auf dem original Namen wieder aufsetzen. Dieses Verfahren funktioniert auch für die NetWorker-StorageUnits, ABER für die StorageUnits die mittels Mtree-Replikation ihre Daten auf das Destination-System kopieren ist es leider unbrauchbar, weil man hierdurch die zugehörige Replikationsbeziehung verliert. Gott sei Dank kam kurz vor der nötigen Entscheidung, entweder noch mal zurück auf die alten Systeme zu schwenken oder alle Mtree-Replikationen neu aufzusetzen, eine weitere Information aus der EMC-Community. Offensichtlich werden alle Informationen der StorageUnit bei der Collection-Replikation übertragen, lediglich der letzte Schritt das Sichtbar machen dieses logischen Elements scheint zu fehlen. Führt man demzufolge eine Veränderung an einer „verborgenen“ StorageUnit durch, dann wird diese plötzlich sichtbar und im Anschluss auch verwendbar.
Nachdem auch diese Hürde genommen war, konnten die Backup-Applikationen wieder starten, dachte man. Aber aus unerfindlichen Gründen gab es auf der Destination-DataDomain dann doch noch ein Problem mit den StorageUnits. Das betraf zwar nur die NetWorker Server, aber diese konnten auf die Destination nicht Clonen. Die Ursache dieses Problems lag darin, dass der NetWorker-Boost Benutzer auf dem neuen DataDomain System eine andere User-ID hatte als auf dem dem Ursprungssystem. Also Mounten der StorageUnit am NetWorker-Server, die Rechte umbiegen und auch dieses Problem war gelöst.
Am nächsten Tag gab es dann Gott sei Dank keine bösen Überraschungen! Alle Backups waren gelaufen, lediglich einige Überwachungsskripte, die per SSH Kommunikation (authorized keys) Daten direkt aus der DataDomain auslesen, konnten keine Daten liefern. Das Problem hier, die Home-Verzeichnisse der DataDomain-Benutzer werden bei der Collection-Replikation nicht mit kopiert. Der Benutzer selbst war aber da (s.o.), man konnte aber leider auch keine neuen SSH-Keys einrichten. Denn das zugehörige Kommando lieferte nur dubiose Fehlermeldungen (can not mkdir …). Auch hier Bestand die Lösung in einem Mount, in dem Falle des DataDomain-Konfigurations-Verzeichnisses (ddvar) und einem händischen Anlegen der zugehörigen Verzeichnisse und Dateien.
Bleibt noch zu erwähnen, dass das gesamte Projekt mittels Fern-Verbindung durchgeführt wurde.
FAZIT:
Die Migration „alter“ DataDomain Systeme auf „neue“ größere und schnellere Systeme konnte wie geplant mit einer überschaubaren Down-Time der Backup-Systeme ohne Datenverluste durchgeführt werden. Leider lässt sich dieses Verfahren nicht mit virtuellen Systemen testen und es gibt wie so oft kleine Stolpersteine auf dem Weg zum Erfolg. Aber für Umgebungen mit DD-Boost Konfigurationen mit zugehörigen Mtree-Replikationen erscheint es weiterhin die einzig praktikable Vorgehensweise zu sein.
Sollten Sie Fragen zum beschriebenen Projekt haben, oder Unterstützung bei einer ähnlichen Herausforderung haben, so scheuen Sie sich bitte nicht den Autor zu kontaktieren, wir finden bestimmt auch eine Lösung für Ihr Problem!
NetWorker 8.xUpdate to NetWorker 9 / 18
Verfasst von Uwe W. Schäfer am 5. Mai 2019
Ja, die NetWorker Version 8.2 ist jetzt schon seit 31. Januar offiziell nicht mehr unter Support, aber dennoch laufen wohl noch eine ganze Menge NetWorker-Server unter dieser Version!
Gerade große NetWorker Konfigurationen, mit mehr als 1000 Clients, Umgebungen die mit externen Schedulern wie Atomic (UC4) und ähnlichem gekoppelt sind, sowie Sicherungen mit langen Aufbewahrungszeiten, bilden für die Umstellung eine sehr große Hürde. Die Probleme bei der Umstellung sind bekanntlich die nötige Anpassung der Skripte, aber auch die Problematik der automatischen Konvertierung der NetWorker 8 Gruppen in eine einzige Policy namens Backup. Sollte der NetWorker 8 aber mehr als 50 Gruppen gehabt haben, wird die NMC nach einer In-Place Migration nicht mehr bedienbar. Ein weiteres nicht zu unterschätzendes Problem bei der Migration besteht darin, dass die Logik des NetWorker 9 lässt sich nicht mit der Logik des NetWorker 8 gleich setzen. Man benötigt folglich für den Update einer großen NetWorker-Umgebung, nicht nur eine Anpassung der bestehenden Datensicherungs-Skripte sondern auch ein neues Konzept und einen Migrationsplan.
Nachdem ich in den letzten 2 Jahren einige In-Place Updates in kleineren Umgebungen und auch Migrationen von großen NetWorker-Umgebungen in eine neue NetWorker 9 Umgebung begleitet habe, kam ein großer Outsourcer auf mich zu, ob ich mit den in diesen Projekten entstandenen Skripten (siehe Blog) in der Lage sei, eine In-Place Migration von NetWorker-Servern mit mehr als 1700 Clients und hunderten von Gruppen zu automatisieren.
Im letzten Monat habe ich nun dieses Projekt abgeschlossen.
Wie funktioniert der implementierte Ansatz?
Die Migration läuft im wesentlichen in 2 Schritten ab.
-
In-Place Migration der NetWorker 8 Datenbanken.
-
zuvor kopieren der NetWorker Ressource DB (/nsr/res/nsrdb)
-
In-Place Migration der NetWorker Umgebung
-
Löschen aller Policys, Protection-Gruppen und auch Clients aus dem NetWorker 9 Server (mit Hilfe eines nsradmin Skriptes)
-
-
Migrieren der NetWorker 8 Client-Ressourcen in die neue NetWorker 9 Umgebung.
-
Anhand eines definierten Algorithmus werden die Client-Attribute der NetWorker-8 Clients wie Gruppe, StorageNode usw. herangezogen, um jeden Client in eine neu definierte NetWorker 9 Policy/Workflow/Protection-Group abzubilden.
- Das Anlegen der neuen Policy/Workflow/Protection-Group Ressourcen wird hierbei mittels REST-API Aufrufen automatisiert erledigt. Die Clients werden wegen fehlender Client-Attribute in der REST-API mit Hilfe von nsradmin-Skripten erzeugt. Das Sammeln der „alten“ Ressource-Attribute, sowie das Anlegen der Clients erfolgt mit Hilfe der Schäfer & Tobies eigenen nsradmin-API.
-
Worin lag das größte Problem bzw. der größte Aufwand bei diesem Projekt?
Die Problematik bestand in einer möglichst genauen Definition der Abbildung der Alten Client-Gruppen-Strucktur auf eine eindeutige Policy/Workflow Struktur. Diese Logik musste in das Migrations-Skript implementiert werden und der Aufwand hierfür war durch fehlende und missverstandene Kommunikationen leider wesentlich höher als erwartet.
Ergebnis des Projektes:
-
Eine NetWorker-Server Migration lässt sich an einem beliebigen NetWorker-Server leicht in wenigen Stunden testen.
-
Die eigentliche In-Place-Migration ist in wenigen Stunden auch für sehr große Umgebungen durchführbar.
-
Die Migrationsquote der getesteten NetWorker-Server mit ca. 1500 und 1700 Clients lag bei 98% bzw. 99%. Clients die aus verschiedenen Gründen nicht in der neuen Umgebung angelegt werden können werden, mit allen Attributen in einer eigenen Datei abgelegt und können von den NetWorker-Administratoren per Hand leicht korrigiert und nach-migriert werden.
FAZIT:
Auch große NetWorker-Umgebungen können mit einem relativ geringem Zeitaufwand auf NetWorker 9/18 In-Place migriert werden! Der Aufwand der Migration wird von der eigentlichen Migrations-Phase auf eine Planung und Implementationsphase verschoben.
Die Vorteile dieses Verfahrens liegen auf der Hand:
-
Durch die In-Place Migration können Langzeitsicherungen ordentlich übernommen werden.
-
Die Migration kann vor dem eigentlichen Umstieg ordentlich getestet werden.
- Der eigentliche Update-Vorgang ist zeitlich überschaubar.
Sollte auch Ihr Unternehmen noch vor dem Update ihrer NetWorker Umgebung stehen, haben sie mit unseren Migrations-Skripten vielleicht eine neue bisher nicht bedachte Möglichkeit der sanften Migration der NetWorker Umgebung. Sprechen Sie uns ruhig unverbindlich an.
NetWorker Ressource Migration; V8.2 -> V9.1
Verfasst von Uwe W. Schäfer am 7. Juli 2017
Halbautomatische Migration der NetWorker V8.2 Client/Gruppen Definition in eine NetWorker V9.1 Workflow Umgebung
1.Kurzbeschreibung
Viele NetWorker Kunden haben in der Version 8.x 100 – 1000 oder sogar mehr Gruppen. Der Extremfall sind 1-3 Gruppen pro Client.
Diese Konstellation ist in NetWorker 9 nicht mehr sinnvoll und EMC warnt vor ähnlichen Konfigurationen. Weil diese nicht getestet und damit auch nicht unterstützt wären.
Im Rahmen eines Kundenprojektes kam nun die Idee auf, die Umstellung der alten Client-Gruppen Struktur möglichst weit zu automatisieren. Entstanden ist ein Skript, das mit Hilfe der NetWorker 8 Konfigurationsdatenbank (/nsr/res/nsrdb) und einer Beschreibungsdatei in der Lage ist, Clients die nach definierten Kriterien aufgebaut bzw. anhand definierbarer Ressource-Attribute selektierbar sind, automatisch in einen definierten NSR9-Workflow zu verschieben.
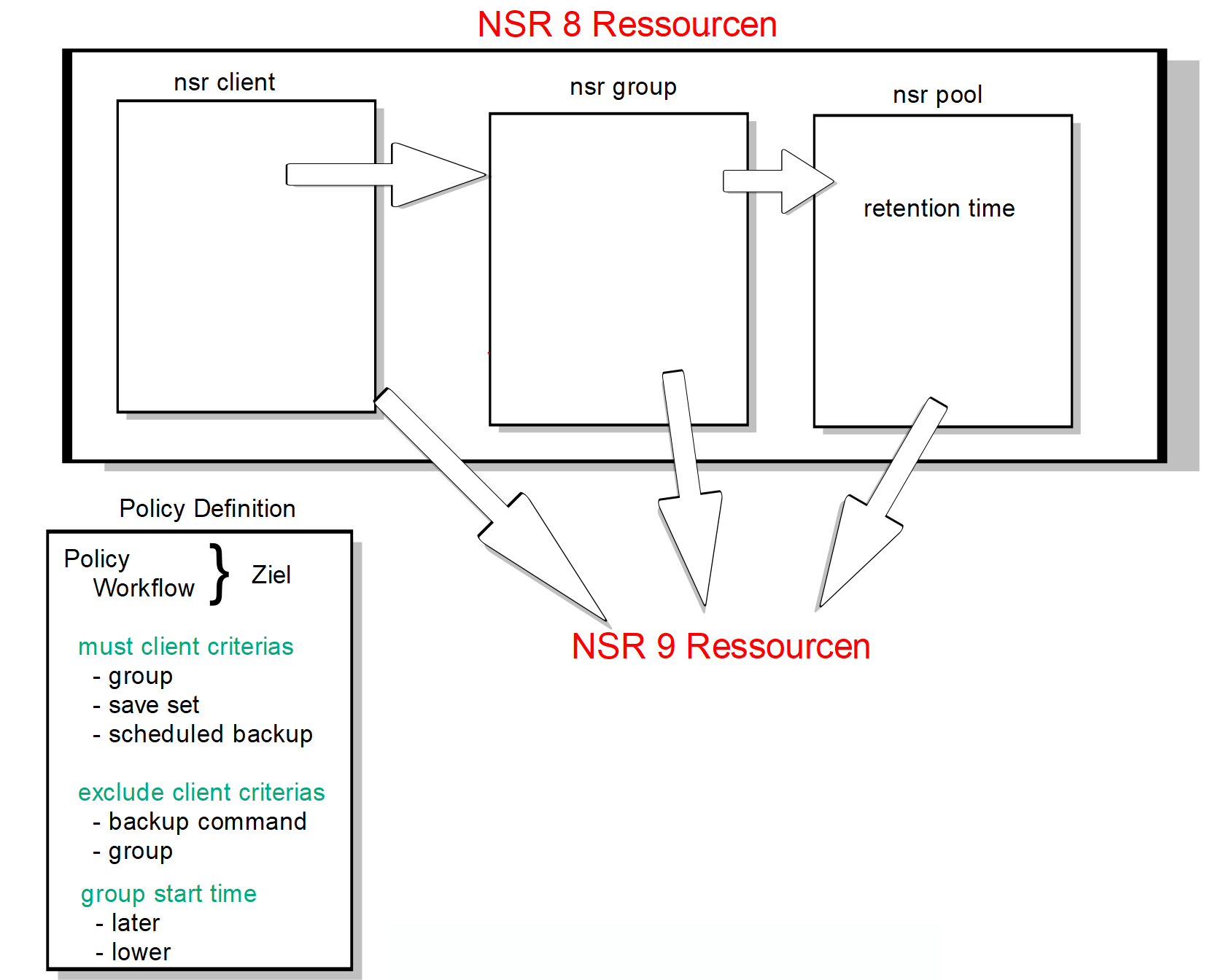
2.Die Definitionsdatei
Mit Hilfe einer der Python Struktur (s.u. „Policy_def“) werden die neuen Ressource-Ziele (Policy-name, Workflow-Name) für die die Client-Ressourcen definiert. Mit Hilfe von Client- und Gruppen-Attributen werden Kriterien für die Aufnahme der Clients in den gegebenen Workflow definiert. Hierbei gibt es nicht nur positive (must criterias), sondern auch ausschließende (false_criterias) Kriterien.
Bei allen Attributen können Listen von gültigen oder ungültigen Werten und auch reguläre Ausdrücke angegeben werden.
Im vorliegenden Fall wurde zusätzlich (in der Definitionsdatei nicht ersichtlich) die „retention policy“ der verwendeten NetWorker Pools in die Migration mit einbezogen und diese wurden den zu migrierenden Clients als „retention policy“ Attribut hinzugefügt. Weitere kundenspezifische Anpassungen sind natürlich denkbar.
Policy_def = {
'Policy-Name' : {
'Workflow-Name' : {
'client_attrs' : {
'must_criterias' : {
'group' : '.*filesystem.*',
'scheduled backup' : 'Enabled',
},
'false_criterias' : {
'backup command' : 'savepnpc',
'group' : ['.*savepnpc.*', ...],
},
},
'group_attrs' : {
'start time' : {
'bigger' : '12:00',
'lower' : '15:00',
},
},
},
'Workflow-Name2' : {
'client_attrs' : {
'must_criterias' : {
'group' : '.*filesystem.*',
'scheduled backup' : 'Enabled',
},
'false_criterias' : {
'backup command' : 'savepnpc',
'group' : ['.*savepnpc.*'],
},
},
'group_attrs' : {
'start time' : {
'bigger' : '18:00',
'lower' : '23:59',
},
},
},
'Policy-Name2' : {
.
.
.
}
3. Der Migrationsablauf
Ein Start des Migrations-Skriptes „move_client.py“ führt dazu, dass bei allen im NetWorker 8 definierten Clients kontrolliert wird, ob sie die definierten Kriterien einer Policy/Workflow Definition entsprechen und wenn ja, werden die Client Attribute „Pool“, „protection group list“ und „retention policy“ für die Client-Ressourcen im bereits laufenden NetWorker 9 verändert.
4.Das Migrations-Skript
USAGE:
move_client.py [-v]* [-n | --TEST] [-s <NSR server>] [-d <nsrdb>] [-p <policy> [-w <workflow>]]
-v verbose
-n TEST
-s <NSR server> NetWorker Server V9 to work on
-d <nsrdb> NetWorker 8 Resource DB
-p <policy> only update the Clients for the given Policy
-w <workflow> only update the Clients for the given Policy and Workflow
Das Skript benötigt eine „alte“ NetWorker 8 Ressource-DB. Diese kann entweder im Aufrufverzeichnis mit dem Namen „nsrdb“ liegen oder der Verzeichnisname der DB kann als Argument übergeben werden.
Achtung: Es sollte eine Kopie der NSR8-Ressource-DB verwendet werden, da auch die DB vom Skript verändert wird.
Wenn das Skript auf dem NetWorker 9 Ziel-Server verwendet wird, wird keine Angabe des Servers benötigt.
Durch die Angaben von Policy und Workflow kann ein erneuter Migrations-Lauf, zum Beispiel nach Änderung der Kriterien für eine spezielle Policy/Workflow Definition, neu durchgeführt werden.
Es empfiehlt sich die Migrations-Definitionen und damit den Test,-des Skriptes auf einem NetWorker 9 Test-Server vor dem eigentlichen Update durch-zuspielen.
Clients, die aus Ausschlussgründen nicht migriert werden konnten, werden in der Standard-Ausgabe des Programms aufgeführt. Zusätzlich wird bei jedem Migrationslauf eine Debug-Datei geschrieben.
5.Fazit
Das hier beschriebene Migrations-Skript kann als Basis für NetWorker 9 Migrationen verwendet werden. Es ist aber keinesfalls sofort einsetzbar, sondern es muss immer eine kundenspezifische Definition der Auswahlattribute stattfinden.
In ungünstigen Fällen kann es auch sein, dass der hier beschriebene Ansatz, zur automatischen Umverteilung der Clients, bei einer Kunden-Umgebung gar nicht funktioniert, z.B. weil es keine brauchbaren Auswahlkriterien gibt.
Sollte auch bei Ihnen die Umstellung von NetWorker 8 auf 9 anstehen und sollten sie in ihrer Umgebung bisher hunderte von Gruppen definiert haben, so scheuen sie sich bitte nicht, uns für die Migrationsunterstützung anzusprechen. Ein unverbindliches Gespräch kostet erst mal nichts, kann ihnen aber sicher weiter helfen.
