NetWorker Capacity Monitoring
Verfasst von Uwe W. Schäfer am 13. November 2019
Wie im letzten Blog (NetWorker Session Monitoring) bereits erwähnt, haben wir unsere Backup-Monitoring Landschaft um eine dritte Komponente erweitert. Zusätzlich zum Monitoring der DataDomain-Streams und den NetWorker Sessions, gibt es jetzt auch die Möglichkeit, den Verlauf der NetWorker „Used Capacity“ für den kompletten NetWorker Server, aber auch für jeden einzelnen Client graphisch zu betrachten.
Sollten Sie ihre NetWorker -Lizenzen auf Basis einer Kapazitäts-Lizenz bezahlen müssen, so ist es auch für sie interessant zu wissen, wie sich die Kapazität der einzelnen zu sichernden Maschinen im Lauf der Zeit verändert. Die NetWorker Reporting Mechanismen sind hierbei leider keine große Hilfe. Diese sind ja noch nicht einmal in der Lage, die aktuell korrekte Kapazitäts-Lizenz-Größe für einen NetWorker-Server zu berechnen (siehe hierzu unseren Blog „NetWorker Volumen Lizenz“ Berechnung).
Hier ein Beispiel-Bild der Lizenz relevanten Sicherungsgrößen („Used Capacity“) für einen SAP-Client und einen MS-SQL-Client.
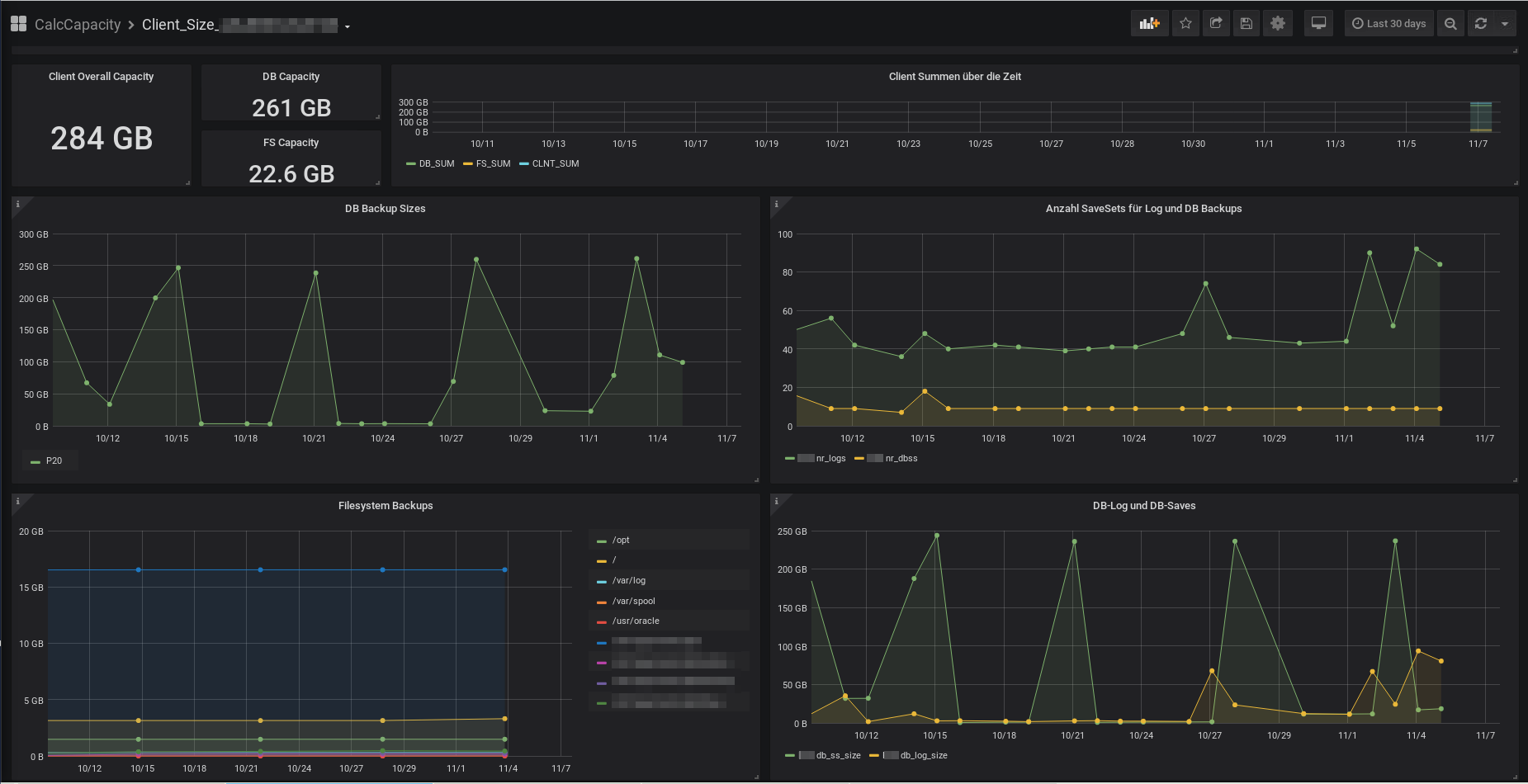
SAP Client
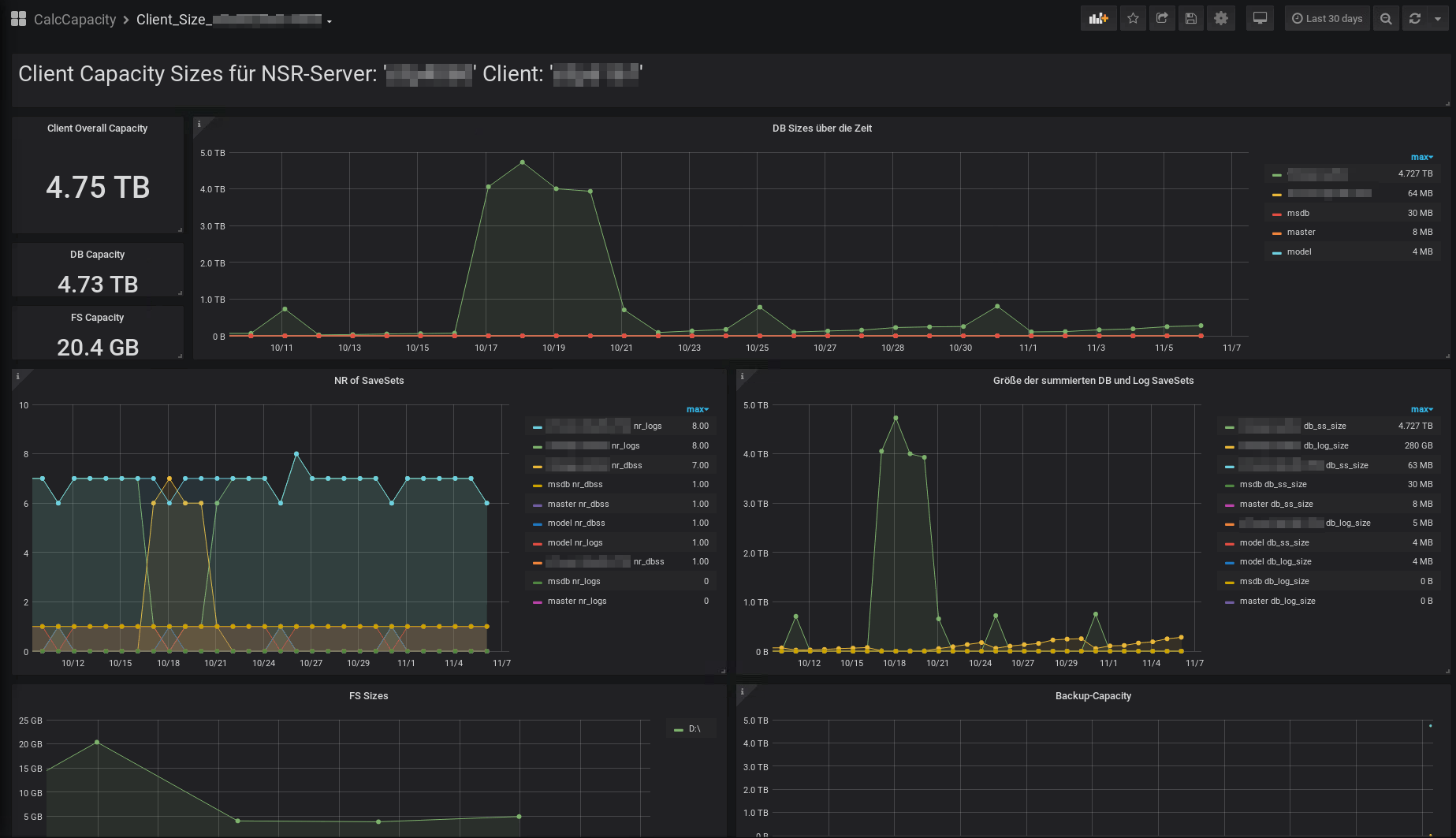
MS-SQL Client Capacity
Aus den obigen Graphiken können zum einen der aktuell für die Berechnung der Volumen-Lizenz relevante Wert, zum anderen die tagesaktuellen Größen der Sicherungsmengen für die Filesystem-Sicherungen, aber vor allem auch für die Datenbank-Sicherungen entnommen werden. Für die Datenbank-Sicherungen erhalten sie nicht nur die zugehörigen Sicherungsgrößen, sondern auch die Anzahl der Sicherungs-SaveSets für die DB und Log-Sicherungen. Hierdurch sollte sich nicht nur das Wachstum der Datensicherungsmenge über die Zeit ermitteln lassen, sondern es sollte auch möglich werden, azyklische Sicherungsmengen, die durch Datenbank-Aktivitäten, wie das neu Befüllen einer Datenbank mit aktiver Log-Sicherung zu erkennen.
Die Grafiken werden anhand von Daten einer PostgresDB und dem Darstellungs-Tool Grafana erzeugt. Die Datenbank wird mit einer Erweiterung des Schäfer & Tobies eigenen Capacity Berechnungstools gefüllt und in einem auf DOCKER basierendem Datenbank-Image eingetragen.
Die oben gezeigten Dashboards können dabei für jeden Client mit Hilfe eines Python-Skriptes voll automatisiert aufgebaut werden. Die Ermittlung der Client-Capacity kann zum Beispiel einmal pro Woche oder einmal pro Monat erfolgen. Die Erzeugung der Daten kann dabei auf jeder beliebigen Linux NetWorker-Client-Maschine durchgeführt werden.
Sollten Sie Fragen zu der hier dargestellten Analyse-Software haben, so senden sie uns bitte unverbindlich eine E-Mail. Wir werden uns mit Ihnen in Verbindung setzen und wenn gewünscht, auch gerne eine Demo der Möglichkeiten mit Hilfe einer Telefon-Konferenz durchführen.
Weitere Informationen zu unseren Monitoring-Tools erhalten sie auch im BLOG „DataDomain Stream Monitoring“ und im Blog „NetWorker Session Monitoring“.
NetWorker Session Monitoring
Verfasst von Uwe W. Schäfer am 11. November 2019
Wie im letzten Blog (DataDomain Monitoring) bereits angekündigt, haben wir auf Basis der Docker-Container-Technik nicht nur ein Monitoring der DataDomain Stream-Auslastung implementiert, sondern auch die Backup-Streams der beteiligten NetWorker-Server grafisch aufbereitet.
Genau genommen können die NetWorker-Sessions aus zwei Blickwinkeln analysiert und dargestellt werden:
- Wie viele Backup- und Cloning Sessions werden vom NetWorker Server an den angeschlossenen DataDomain Systemen erzeugt.
- Welche Workflows erzeugen wann wie viele parallele Streams.
Für beide Blickwinkel werden für jeden NetWorker-Server eigene Tabellen in einer Influx-Datenbank gefüllt. Diese können in einer jeweils eigenen Darstellungs-Seite im graphischen Analyse-Tool Grafana betrachtet und analysiert werden.
Die folgenden 3 Grafiken zeigen zunächst die Anzahl Sessions pro DataDomain und pro NetWorker Laufwerk:

In der obigen Grafik wird die Anzahl von parallelen NetWorker-Sessions der letzten 7 Tage dargestellt. In der ersten Zeile erkennt man in der Tachometer Darstellung, die maximale Anzahl Sessions für die beiden DataDomain Systeme in den Kategorien Save, Recover, Clone-Saves und Clone-Recover. In den darunter folgenden Grafiken erkennt man den Verlauf der jeweiligen Session-Anzahl pro Laufwerk. Durch einen Mausklick auf einen der Laufwerksnamen, kann man sich den Verlauf für ein einzelnes Laufwerk anzeigen lassen.
Möchte man die Auslastung des letzen Tages, oder eines beliebigen anderen Zeitraums anzeigen lassen, so kann man dieses leicht über die Grafana WWW-Oberfläche per Menu-Auswahl oder per Maus-Auswahl erreichen.
Die Darstellung der letzten 24 Stunden:

Die Darstellung eines mit der Maus ausgewählten Zeitraum von ca. 2 Stunden:

Wie oben schon erwähnt, möchte man aber nicht nur die Summe der Sessions zum jeweiligen Zeitpunkt betrachten, sondern in bestimmten Fällen ist es auch interessant zu ermitteln, welcher Workflow hat denn die zu hohe Last produziert. Auch zu dieser Darstellung 3 Beispiel-Bilder:
Die Darstellung der Sessions pro Workflow der letzten 7 Tage:

Die Workflow Sessions der letzten 24 Stunden:

Ein mit Hilfe der Maus ausgewählter Zeitraum von ca. 2 Stunden:

Wozu man die Grafiken verwenden kann, sollte jedem NetWorker-Administrator leicht ersichtlich sein. Man erkennt zum Beispiel eventuelle Engpässe, freie Zeiträume und so weiter. Im Falle des Einsatzes von mehreren NetWorker Servern, lassen sich so aber auch die Sicherungszeiten und deren Lastverteilung zwischen den NetWorker-Servern vergleichen, um so eine Basis für bessere Auslastung der DataDomain Systeme zu erhalten, die Datensicherungen zu optimieren und die Probleme zu minimieren.
Technische Implementation:
Noch einige Sätze zur technischen Implementierung und zu den benötigten Ressourcen.
Die gesamte Lösung besteht aus 3 Docker-Images. Ein Image stellt die Datenbank zur Verfügung. Es handelt sich hierbei um die freie NON-SQL Datenbank Influx-DB. Das zweite Image dient der Darstellung der gesammelten Daten. Hier wird wie bereits bei der DataDomain-Monitoring Lösung auf Grafana zurückgegriffen. Das dritte Image ist das Aufzeichnungsimage. Dieses Schäfer & Tobies eigene Image basiert auf einem Ubuntu-Image mit einem integrierten NetWorker-Client und einem Python-Script, das alle ‚n‘ Sekunden die aktuellen Session-Informationen vom NetWorker-Server abfragt. Die Abfragen erfolgen hierbei zum einen mit der NetWorker-REST-API, zum anderen mit dem Command-Line-Tool „nsradmin“. Das dritte Image wird ganz Docker-Like pro NetWorker-Server ausgerollt. Sollten sie z.B. 3 NetWorker Server im Einsatz haben, so benötigen sie für die oben gezeigten Aufzeichnungen folglich 5 Docker-Instanzen. Sollten sie auch die zwei DataDomain Systeme monitoren wollen, so benötigen sie insgesamt 7 Docker-Instanzen auf Basis von 4 verschiedenen Images. Die hier gezeigte Lösung ist somit sehr flexible und sowohl für kleinere NetWorker-Umgebungen als auch für große einsetzbar.
Fazit:
Mit dem Schäfer & Tobies eigenen NetWorker-Monitoring Skripten können Sie Engpässe in Ihren Datensicherungsabläufen erkennen. Ungenutzte Zeiträume, aber auch eventuelle Engpässe und Überlastungen kann man mit den Grafana basierten Grafiken gut analysieren. Beim Einsatz von mehreren NetWorker-Servern können die Zeiten der höchsten Anforderungen der einzelnen Backup-Server leicht gegeneinander verglichen werden.
Sollten Sie Fragen zu der hier dargestellten Analyse-Software haben, so senden sie uns bitte unverbindlich eine E-Mail. Wir werden uns mit Ihnen in Verbindung setzen und wenn gewünscht, auch gerne eine Demo der Möglichkeiten mit Hilfe einer Telefon-Konferenz durchführen.
Weitere Informationen zu unseren Monitoring-Tools erhalten sie auch im BLOG „DataDomain Monitoring“ und in Kürze im Blog „Grafische NetWorker Kapazitätsauswertung“.
DataDomain Stream Monitoring
Verfasst von Uwe W. Schäfer am 8. November 2019
Seit einiger Zeit plagten sich einige unserer Kunden und damit auch ich, mit den Problemen, wie kann man bei der Sicherung auf DataDomain Systemen feststellen:
-
warum laufen Sicherungen mal schneller oder mal langsamer?
-
warum wurden DataDomain-Cloning Aufträge erst nach mehreren „Retrys“ durchgeführt oder gar ganz abgebrochen?
-
wie hoch war die Auslastung der DataDomain Streams zum Zeitpunkt ‚X‘?
Eine Antwort auf die letzte Frage war bisher nur sehr schwer möglich. Die DataDomain Systeme haben keine native Möglichkeit, die Anzahl der aktiven Streams nachträglich anzuzeigen. Die einzige Information zu den aktiven Streams, die man meines Wissensstandes nach erhalten kann, ist eine Text-Ausgabe der verwendeten Streams pro Storage-Unit mit Hilfe des Kommandos „ddboost streams show“. Um aus diesen ASCII-Werten jedoch eine brauchbare Ausgabe zu erzeugen, die es ermöglicht am Montag nachzuschauen, wie die Auslastung des Systems am Samstag um 23:15 war und dabei auch noch sagen zu können, welcher Backup-Server war Schuld an der Überlastung des Systems: bedarf es etwas mehr, als die Ist-Werte eines Kommandos in einer ASCII-Datei abzulegen.
Das Ziel war eine Oberfläche zu schaffen, in der man für jeden beliebigen Zeitpunkt in den letzten „n‘ Monaten sagen kann, wie viele Sessions liefen um die Uhrzeit ‚X‘. Welche Storage-Unit und daraus folgernd welche Backup-Applikation hat zu dem Zeitpunkt ‚X‘ wie viele Sessions belegt.
Das Ergebnis:

DataDomain Monitoring über 7 Tage
Auf dieser Grafik können sie die Auslastung eines DataDomain System über die letzten 7 Tage betrachten. Das System hat 6 Storage-Units, also 6 unterschiedliche Systeme die gleichzeitig mit der DataDomain arbeiten. Die 4 Balkendiagramme zeigen die Anzahl der Session für Read, Write und Replikation-In und -Out an. Oberhalb der Balkendiagramme erkennt man in einem Tachometer die maximale Anzahl Sessions in dem gewählten Zeitfenster, sowie die maximal mögliche Anzahl von Sessions auf dem System. Man kann also auf dem obigen Bild leicht erkennen, dass das System noch reichlich Luft nach oben hat. Dennoch ermöglicht die Darstellung das Auslesen einiger interessanter Informationen. Aber schauen wir uns zunächst mal eine andere Zeitscheibe der Aufzeichnung an.
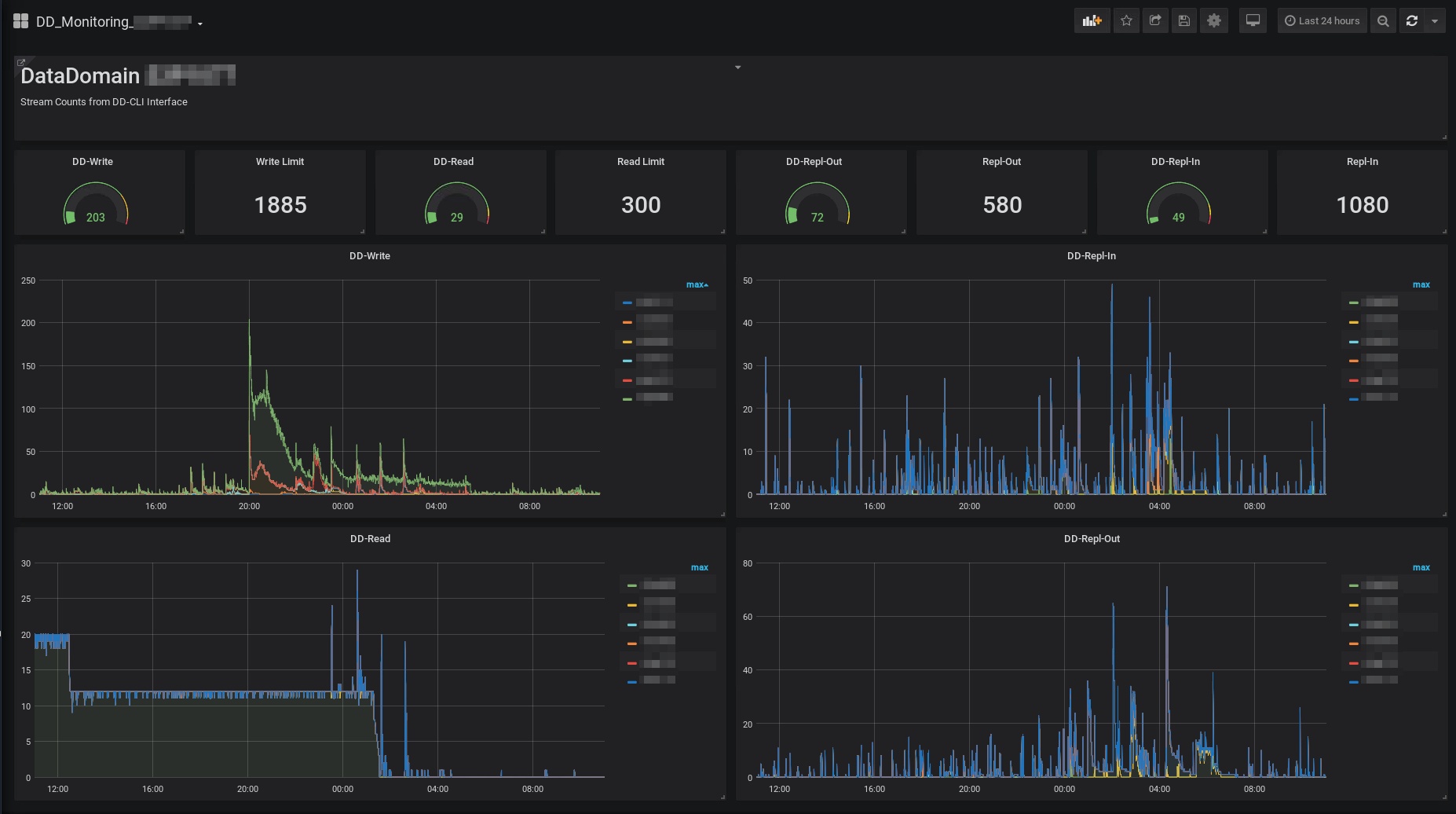
Auf dieser Darstellung lassen sich schon etwas genauere Informationen auslesen. Z.B. welcher Sicherungsserver generiert die meisten Streams. Wann beginnt die Datensicherung auf den Servern. Eventuell hilft diese Darstellung schon den problematischen Zeitpunkt zu erkennen und das Problem durch eine Verlagerung der Sicherungszeiten zu entschärfen.
Um noch genauer hinschauen zu können, können wir uns aber auch einen beliebigen Zeitraum heranzoomen.
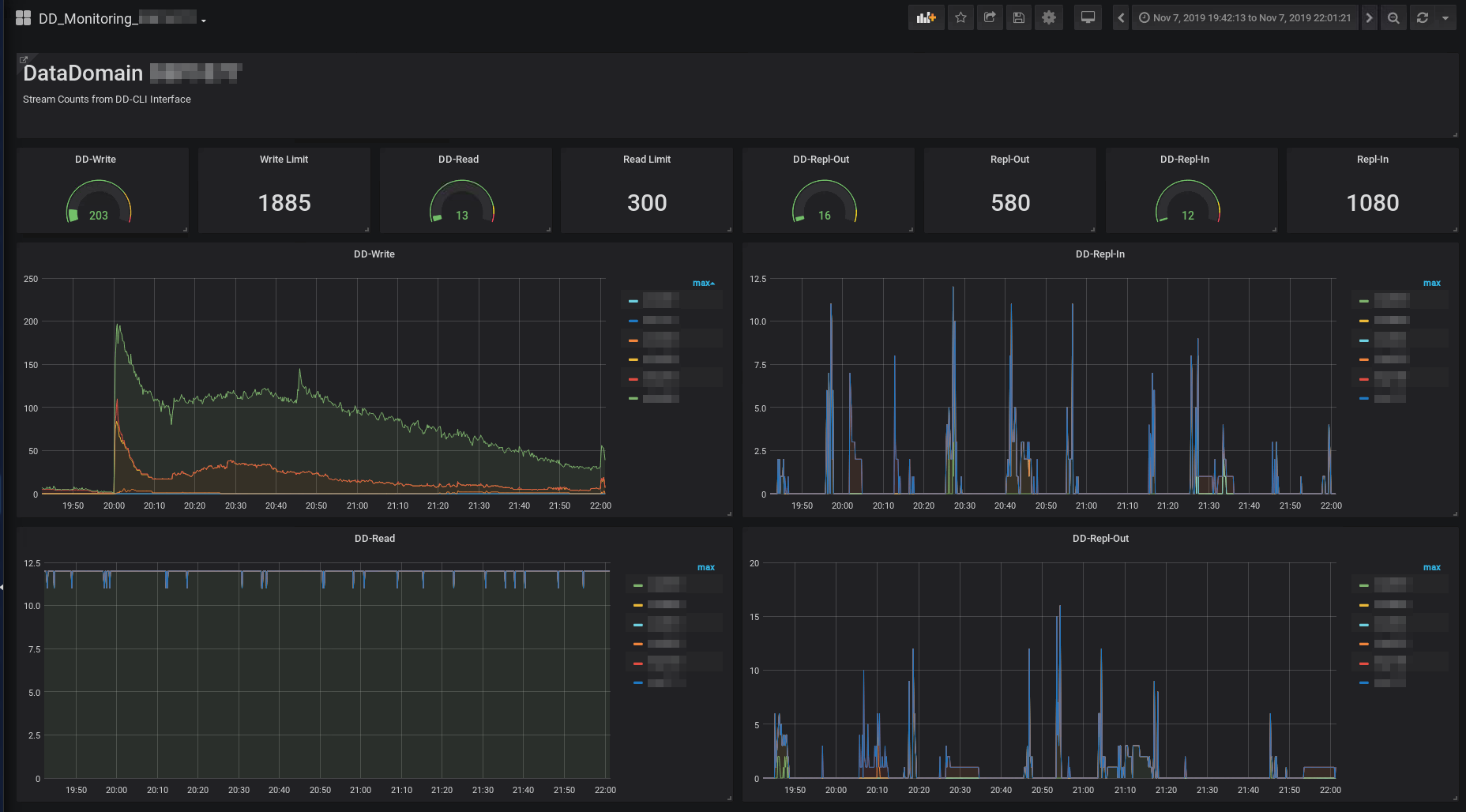 Darstellung der DataDomain-Streams von 20:00 – 22:00
Darstellung der DataDomain-Streams von 20:00 – 22:00
Jetzt erkennt man sehr detailliert dass in dem per Maus gewählten Zeitraum (siehe oben in der Menuleiste) 2 Server gleichzeitig mit den Sicherungsarbeiten begonnen haben. Außerdem lässt sich gut erkennen, dass währen des gesamten Zeitraums ein Server einen Wiederherstellungsauftrag mit 12 parallelen Sessions durchgeführt hat. Die parallel laufenden Replikationen waren wohl eher unkritisch.
Implementierung:
Was wird benötigt um diese Grafiken auf Basis eines interaktiven WWW-Fensters zu erhalten? Die ganze Implementierung setzt auf Software-Containern auf. Um genau zu sein, kommen DOCKER-Container auf Basis einer Docker-Maschine oder eines Kubernetis-Clusters zum Einsatz. In dem hier gezeigten Falle wurden 3 Container verwendet. Ein-Container sammelt mit Hilfe von Python-Programmen die Auslastungs-Daten ein und sendet diese an eine Datenbank. Die Datenbank befindet sich im zweiten Container. Der dritte Container beinhaltet das Auswertetool Grafana. Mit Hilfe eines beliebigen WWW-Browsers kann man die Datenbank mit Grafana verknüpfen und erhält die hier gezeigten Grafiken. Sollten mehrere DataDomain Systeme betrachtet werden, so wird pro DataDomain-System ein Aufzeichnungs-Container gestartet. Auch die Sicherheit kommt bei dieser Implementierung nicht zu kurz. Die Werte aus dem DataDomain-System werden mit Hilfe einer SSH-Verbindung von einem Read-Only-Benutzer ermittelt. Die Datenbank ist nur innerhalb der DOCKER-Umgebung bzw. innerhalb des Kubernetis-Clusters sichtbar. Die Grafana WWW-Seite verlangt eine Benutzer-Autorisierung.
Fazit:
Mit Hilfe einer DOCKER-Umgebung, einer freien Datenbank (Influx-DB), dem frei verfügbaren Darstellungsmodul Grafana und unseren Aufzeichnungsskripten, kann man die Auslastung einer DataDomain, aber auch das Lastverhalten der Sicherungs-Server Minutengenau analysieren.
Sollten Sie Interesse an der hier gezeigten Lösung haben, so scheuen Sie sich bitte nicht uns zu kontaktieren. Sollten Sie zusätzlich zur DataDomain auch noch das Backup-Produkt NetWorker im Einsatz haben, dann sollten sie sich auch unseren Blog NetWorker-Session- Monitoring anschauen.
Parallelisierung von NDMP Backups
Verfasst von Uwe W. Schäfer am 25. Oktober 2019
Automatische Generierung von NDMP SaveSet Namen
Ein Kunde hatte das Problem, dass die Sicherungszeit eines NetApp-Volumes mit ca. 40 TB Größe, mehrere Tage betrug. Außerdem waren die Wiederherstellungszeiten für einzelne Dateien aus diesen Sicherungen inakzeptabel.
Eine einfache Parallelisierung der Verzeichnisse von Hand war leider nicht möglich, da sich bereits auf der obersten Verzeichnisebene mehr als 8000 Unterverzeichnisse befanden. Erschwerend kam hinzu, dass jederzeit auch neue Unterverzeichnisse von den Fachabteilungen angelegt werden können. Diese müssen natürlich auch bei der nächsten anstehenden Sicherung mitgesichert werden.
Es stellte sich folglich das Problem: wie kann man die Sicherung des Volumes parallelisieren, ohne Gefahr zu laufen, neu angelegte Verzeichnisse nicht zu sichern.
Die Lösung bestand in der Programmierung eines Python-Skriptes, das mit Hilfe der Schäfer & Tobies eigenen NetApp-Ontapi-Python Schnittstelle und dem NetWorker-REST-API, täglich die NetWorker Client-Ressourcen automatisiert neu generiert.
Das Skript liest hierzu zunächst alle Unterverzeichnisnamen des Volumes per API aus und verteilt die erhaltenen Namen anhand einer Konfigurationstabelle und den Anfangsbuchstaben auf „n“ definierte NetWorker-Client-Ressourcen. Jede dieser NetWorker Client-Ressourcen verwendet einen eigenen Schedule, so dass auch eine Verteilung der Vollsicherungen über die Wochentage erfolgt.
Das Ergebnis konnte sich sehen lassen, die Sicherungszeiten waren wieder im vertretbaren Rahmen (unter 24 Stunden) und auch die Wiederherstellungszeiten sind um ein vielfaches schneller als zuvor.
Sollten Sie ein ähnliches Problem in ihrer Sicherungsumgebung haben, so scheuen Sie sich nicht, den Autor zu kontaktieren. Eine automatisierte und damit sichere Generierung der NetWorker-Ressourcen garantiert auch Ihnen, dass ihre wichtigen Daten immer in der aktuellen Sicherung enthalten sind. Der Aufwand für die Erstellung der benötigten Skripte hält sich in überschaubaren Grenzen und sollte damit auch für ihre Firma erschwinglich sein.
